用Linux和Apache Hadoop進行云計算
<TABLE id=table1 class=content border=0 cellSpacing=0 cellPadding=0 width=321>
<TD class=left-nav-highlight>本文內容包括:</TD></TR>
<TR class=left-nav-child-highlight>
IBM?、Google、VMWare 和 Amazon 等公司已經開始提供云計算產品和戰略。本文講解如何使用 Apache Hadoop 構建一個 MapReduce 框架以建立 Hadoop 集群,以及如何創建在 Hadoop 上運行的示例 MapReduce 應用程序。還將討論如何在云上設置耗費時間/磁盤的任務。
云計算簡介
近來云計算越來越熱門了,云計算已經被看作 IT 業的新趨勢。云計算可以粗略地定義為使用自己環境之外的某一服務提供的可伸縮計算資源,并按使用量付費。可以通過 Internet 訪問 “云” 中的任何資源,而不需要擔心計算能力、帶寬、存儲、安全性和可靠性等問題。
本文簡要介紹 Amazon EC2 這樣的云計算平臺,可以租借這種平臺上的虛擬 Linux? 服務器;然后介紹開放源碼 MapReduce 框架 Apache Hadoop,這個框架將構建在虛擬 Linux 服務器中以建立云計算框架。但是,Hadoop 不僅可以部署在任何廠商提供的 VM 上,還可以部署在物理機器上的一般 Linux OS 中。
在討論 Apache Hadoop 之前,我們先簡要介紹一下云計算系統的結構。圖 1 顯示云計算的各個層以及現有的一些服務。關于云計算的各個層的詳細信息,請參見 參考資料。
基礎設施即服務 (Infrastructure-as-a-Service,IaaS)是指以服務的形式租借基礎設施(計算資源和存儲)。IaaS 讓用戶可以租借計算機(即虛擬主機)或數據中心,可以指定特定的服務質量約束,比如能夠運行某些操作系統和軟件。Amazon EC2 在這些層中作為 IaaS,向用戶提供虛擬的主機。平臺即服務 (Platform-as-a-Service,PaaS)主要關注軟件框架或服務,提供在基礎設施中進行 “云” 計算所用的 API。Apache Hadoop 作為 PaaS,它構建在虛擬主機上,作為云計算平臺。
圖 1. 云計算的層和現有服務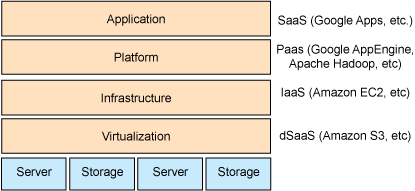
Amazon EC2
Amazon EC2 是一個 Web 服務,它允許用戶請求具有各種資源(CPU、磁盤、內存等)的虛擬機器。用戶只需按使用的計算時間付費,其他事情全交給 Amazon 處理。
這些實例 (Amazon Machine Image,AMI) 基于 Linux,可以運行您需要的任何應用程序或軟件。在從 Amazon 租借服務器之后,可以像對待物理服務器一樣使用一般的 SSH 工具設置連接和維護服務器。
對 EC2 的詳細介紹超出了本文的范圍。更多信息請參見 參考資料。
部署 Hadoop 云計算框架的最好方法是把它部署在 AMI 上,這樣可以利用云資源,不需要考慮計算能力、帶寬、存儲等問題。但是,在本文的下一部分中,我們將在本地的 Linux 服務器 VMWare 映像中構建 Hadoop,因為 Hadoop 不僅適用于云解決方案。在此之前,我們先介紹一下 Apache Hadoop。
Apache Hadoop
Apache Hadoop 是一個軟件框架(平臺),它可以分布式地操縱大量數據。它于 2006 年出現,由 Google、Yahoo! 和 IBM 等公司支持。可以認為它是一種 PaaS 模型。
它的設計核心是 MapReduce 實現和 HDFS (Hadoop Distributed File System),它們源自 MapReduce(由一份 Google 文件引入)和 Google File System。
MapReduce 是 Google 引入的一個軟件框架,它支持在計算機(即節點)集群上對大型數據集進行分布式計算。它由兩個過程組成,映射(Map)和縮減(Reduce)。
在映射過程中,主節點接收輸入,把輸入分割為更小的子任務,然后把這些子任務分布到工作者節點。
工作者節點處理這些小任務,把結果返回給主節點。
然后,在縮減過程中,主節點把所有子任務的結果組合成輸出,這就是原任務的結果。
圖 2 說明 MapReduce 流程的概念。
MapReduce 的優點是它允許對映射和縮減操作進行分布式處理。因為每個映射操作都是獨立的,所有映射都可以并行執行,這會減少總計算時間。
對 HDFS 及其使用方法的完整介紹超出了本文的范圍。更多信息請參見 參考資料。
從最終用戶的角度來看,HDFS 就像傳統的文件系統一樣。可以使用目錄路徑對文件執行 CRUD 操作。但是,由于分布式存儲的性質,有 “NameNode” 和 “DataNode” 的概念,它們承擔各自的責任。
NameNode 是 DataNode 的主節點。它在 HDFS 中提供元數據服務。元數據說明 DataNode 的文件映射。它還接收操作命令并決定哪些 DataNode 應該執行操作和復制。
DataNode 作為 HDFS 的存儲塊。它們還響應從 NameNode 接收的塊創建、刪除和復制命令。
在提交應用程序時,應該提供包含在 HDFS 中的輸入和輸出目錄。JobTracker 作為啟動 MapReduce 應用程序的單一控制點,它決定應該創建多少個 TaskTracker 和子任務,然后把每個子任務分配給 TaskTracker。每個 TaskTracker 向 JobTracker 報告狀態和完成后的任務。
通常,一個主節點作為 NameNode 和 JobTracker,從節點作為 DataNode 和 TaskTracker。Hadoop 集群的概念視圖和 MapReduce 的流程見圖 2。
圖 2. Hadoop 集群的概念視圖和 MapReduce 的流程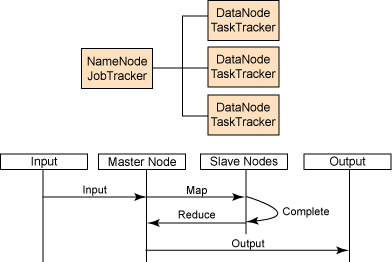
設置 Apache Hadoop
現在在 Linux VM 上設置 Hadoop 集群,然后就可以在 Hadoop 集群上運行 MapReduce 應用程序。
Apache Hadoop 支持三種部署模式:
- 單獨模式:在默認情況下,Hadoop 以非分布的單獨模式運行。這個模式適合應用程序調試。
- 偽分布模式:Hadoop 還可以以單節點的偽分布模式運行。在這種情況下,每個 Hadoop 守護進程作為單獨的 Java? 進程運行。
- 全分布模式:Hadoop 配置在不同的主機上,作為集群運行。
要想以單獨或偽分布模式設置 Hadoop,請參考 Hadoop 的網站。在本文中,我們只討論以全分布模式設置 Hadoop。
在本文中,我們需要三臺 GNU/Linux 服務器;一個作為主節點,另外兩個作為從節點。
表 1. 服務器信息| 服務器 IP | 服務器主機名 | 角色 |
| 9.30.210.159 | Vm-9-30-210-159 | 主節點(NameNode 和 JobTracker) |
| 9.30.210.160 | Vm-9-30-210-160 | 從節點 1 (DataNode 和 TaskTracker) |
| 9.30.210.161 | Vm-9-30-210-161 | 從節點 2 (DataNode 和 TaskTracker) |
每臺機器都需要安裝 Java SE 6 和 Hadoop 二進制代碼。更多信息見 參考資料。本文使用 Hadoop version 0.19.1。
還需要在每臺機器上安裝 SSH 并運行 sshd。SUSE 和 RedHat 等流行的 Linux 發行版在默認情況下已經安裝了它們。
更新 /etc/hosts 文件,確保這三臺機器可以使用 IP 和主機名相互通信。
因為 Hadoop 主節點使用 SSH 與從節點通信,所以應該在主節點和從節點之間建立經過身份驗證的無密碼的 SSH 連接。在每臺機器上執行以下命令,從而生成 RSA 公共和私有密鑰。
ssh-keygen –t rsa |
這會在 /root/.ssh 目錄中生成 id_rsa.pub。重命名主節點的 id_rsa.pub(這里改名為 59_rsa.pub)并把它復制到從節點。然后執行以下命令,把主節點的公共密鑰添加到從節點的已授權密鑰中。
cat /root/.ssh/59_rsa.pub >> /root/.ssh/authorized_keys |
現在嘗試使用 SSH 連接從節點。應該可以成功連接,不需要提供密碼。
把 Hadoop 設置為全分布模式需要配置 <Hadoop_home>/conf/ 目錄中的配置文件。
在 hadoop-site.xml 中配置 Hadoop 部署。這里的配置覆蓋 hadoop-default.xml 中的配置。
表 2. 配置屬性| 屬性 | 解釋 |
| fs.default.name | NameNode URI |
| mapred.job.tracker | JobTracker URI |
| dfs.replication | 復制的數量 |
| hadoop.tmp.dir | 臨時目錄 |
hadoop-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://9.30.210.159:9000</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>9.30.210.159:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp/</value>
</property>
</configuration>
|
通過配置 hadoop-env.sh 文件指定 JAVA_HOME。注釋掉這一行并指定自己的 JAVA_HOME 目錄。
export JAVA_HOME=<JAVA_HOME_DIR> |
在 master 文件中添加主節點的 IP 地址。
9.30.210.159 |
在 slave 文件中添加從節點的 IP 地址。
9.30.210.160 9.30.210.161 |
把 hadoop-site.xml、hadoop-env.sh、masters 和 slaves 復制到每個從節點;可以使用 SCP 或其他復制工具。
運行以下命令對 HDFS 分布式文件系統進行格式化。
<Hadoop_home>/bin/hadoop namenode -format |
現在,可以使用 bin/start-all.sh 啟動 Hadoop 集群。命令輸出指出主節點和從節點上的一些日志。檢查這些日志,確認一切正常。如果弄亂了什么東西,可以格式化 HDFS 并清空 hadoop-site.xml 中指定的臨時目錄,然后重新啟動。
訪問以下 URL,確認主節點和從節點是正常的。
NameNode: http://9.30.210.159:50070 JobTracker: http://9.30.210.159:50030 |
現在,已經在云中設置了 Hadoop 集群,該運行 MapReduce 應用程序了。
創建 MapReduce 應用程序
MapReduce 應用程序必須具備 “映射” 和 “縮減” 的性質,也就是說任務或作業可以分割為小片段以進行并行處理。然后,可以縮減每個子任務的結果,得到原任務的結果。這種任務之一是網站關鍵字搜索。搜索和抓取任務可以分割為子任務并分配給從節點,然后在主節點上聚合所有結果并得到最終結果。
Hadoop 附帶一些用于測試的示例應用程序。其中之一是單詞計數器,它統計某一單詞在幾個文件中出現的次數。通過運行這個應用程序檢查 Hadoop 集群。
首先,把輸入文件放在分布式文件系統中(conf/ 目錄下面)。我們將統計單詞在這些文件中出現的次數。
$ bin/hadoop fs –put conf input |
然后,運行這個示例應用程序,以下命令統計以 “dfs” 開頭的單詞出現的次數。
$ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+' |
命令的輸出說明映射和縮減過程。
前兩個命令會在 HDFS 中生成兩個目錄,“input” 和 “output”。可以使用以下命令列出它們。
$ bin/hadoop fs –ls |
查看分布式文件系統中已經輸出的文件。它以鍵-值對的形式列出以 “dfs*” 開頭的單詞出現的次數。
$ bin/hadoop fs -cat ouput/* |
現在,訪問 JobTracker 站點查看完成的作業日志。
創建 Log Analyzer MapReduce 應用程序
現在創建一個 Portal (IBM WebSphere? Portal v6.0) Log Analyzer 應用程序,它與 Hadoop 中的 WordCount 應用程序有許多共同點。這個分析程序搜索所有 Portal 的 SystemOut*.log 文件,顯示在特定的時間段內應用程序在 Portal 上啟動了多少次。
在 Portal 環境中,所有日志分割為 5MB 的片段,很適合由幾個節點并行地分析。
hadoop.sample.PortalLogAnalyzer.javapublic class PortalLogAnalyzer { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private static String APP_START_TOKEN = "Application started:"; private Text application = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); if(line.indexOf(APP_START_TOKEN) > -1) { int startIndex = line.indexOf(APP_START_TOKEN); startIndex += APP_START_TOKEN.length(); String appName = line.substring(startIndex).trim(); application.set(appName); output.collect(application, new IntWritable(1)); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while(values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws IOException { JobConf jobConf = new JobConf(PortalLogAnalyzer.class); jobConf.setJobName("Portal Log Analizer"); jobConf.setOutputKeyClass(Text.class); jobConf.setOutputValueClass(IntWritable.class); jobConf.setMapperClass(Map.class); jobConf.setCombinerClass(Reduce.class); jobConf.setReducerClass(Reduce.class); jobConf.setInputFormat(TextInputFormat.class); jobConf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(jobConf, new Path(args[0])); FileOutputFormat.setOutputPath(jobConf, new Path(args[1])); JobClient.runJob(jobConf); } } |
對 Hadoop API 的完整解釋請參見 Hadoop 網站上的 API 文檔。這里只做簡要說明。
Map 類實現映射功能,它搜索日志文件的每一行,尋找應用程序的名稱。然后把應用程序名稱以鍵-值對的形式放在輸出集合中。
Reduce 類計算具有相同鍵(相同應用程序名稱)的所有值的總和。因此,這個應用程序最終輸出的鍵-值對表示每個應用程序在 Portal 上啟動的次數。
Main 函數配置并運行 MapReduce 作業。
首先,把這些 Java 代碼復制到主節點并編譯。把 Java 代碼復制到 <hadoop_home>/workspace 目錄中。對它執行編譯并存檔在一個 Jar 文件中,后面 hadoop 命令將運行這個文件。
$ mkdir classes
$ javac –cp ../hadoop-0.19.1-core.jar –d classes
hadoop/sample/PortalLogAnalyzer.java
$ jar –cvf PortalLogAnalyzer.jar –C classes/ . |
把 Portal 日志復制到 workspace/input 中。假設有多個日志文件,其中包含 2009 年 5 月的所有日志。把這些日志放到 HDFS 中。
$ bin/hadoop fs –put workspace/input input2 |
在運行 PortalLogAnalyzer 時,輸出說明映射和縮減過程。
$ bin/hadoop jar workspace/PortalLogAnalizer.jar hadoop.sample.PortalLogAnalizer input2
output2 |
圖 3. 任務的輸出
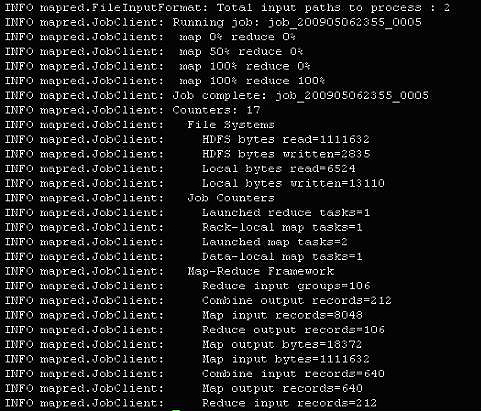
應用程序執行完之后,輸出應該與圖 4 相似。
$ bin/hadoop fs –cat output2/* |
圖 4. 部分輸出
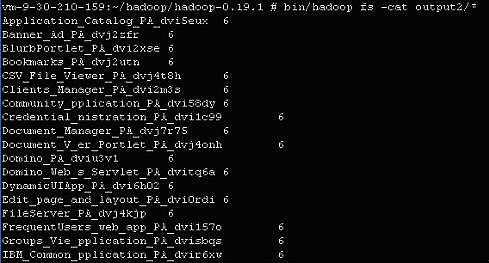
在訪問 JobTracker 站點時,會看到另一個完成的作業。注意圖 5 中的最后一行。
圖 5. 完成的作業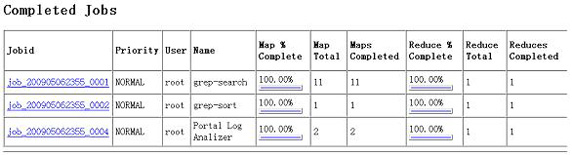
參考資料
- Linux 上的云計算深入討論云計算,介紹它的各個方面。
- Architectural manifesto: An introduction to the possibilities (and risks) of cloud computing介紹云計算帶來的可能性和風險。
- 使用 Linux 和 Hadoop 進行分布式計算介紹 Hadoop 框架,解釋它為什么是最重要的基于 Linux 的分布式計算框架之一。
- 用 Amazon Web Services 進行云計算,第 3 部分: 用 EC2 根據需要提供服務器 介紹 Amazon Elastic Compute Cloud (EC2) 提供的虛擬服務器。
- Apache Hadoop 網站 提供 API 文檔、教程、命令參考和下載等。
- 了解關于 MapReduce 的基本知識。
- Java SE6 Release Notes 提供關于安裝 Java SE 6 的信息。
- AIX and UNIX 專區:developerWorks 的“AIX and UNIX 專區”提供了大量與 AIX 系統管理的所有方面相關的信息,您可以利用它們來擴展自己的 UNIX 技能。
- AIX and UNIX 新手入門:訪問“AIX and UNIX 新手入門”頁面可了解更多關于 AIX 和 UNIX 的內容。
- AIX and UNIX 專題匯總:AIX and UNIX 專區已經為您推出了很多的技術專題,為您總結了很多熱門的知識點。我們在后面還會繼續推出很多相關的熱門專題給您,為了方便您的訪問,我們在這里為您把本專區的所有專題進行匯總,讓您更方便的找到您需要的內容。
